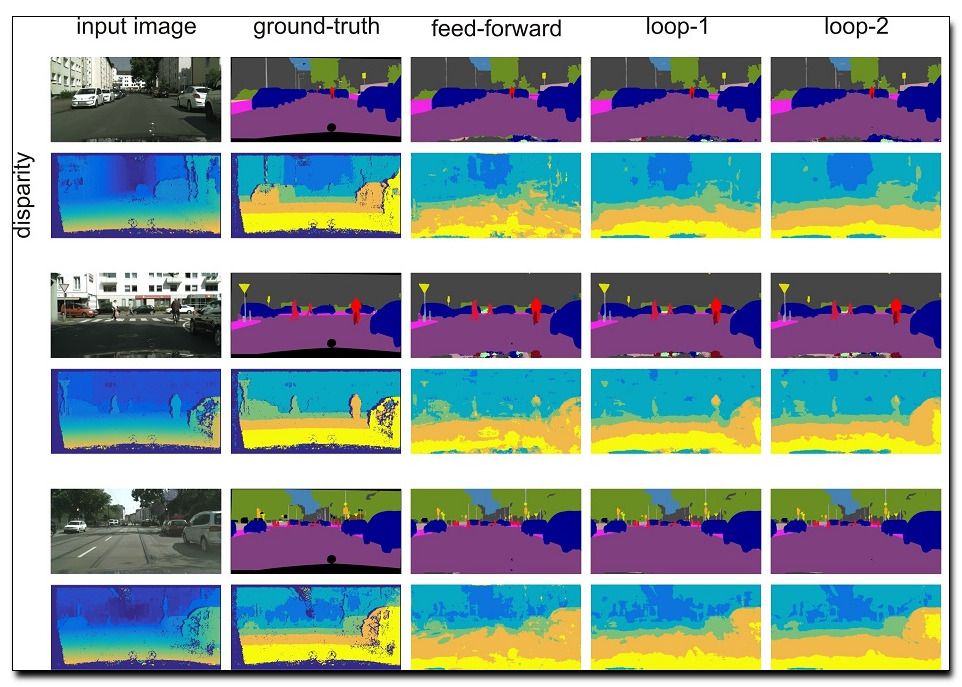
Objects may appear at arbitrary scales in perspective images of a scene, posing a challenge for recognition systems that process an image at a fixed resolution. We propose a depth-aware gating module that adaptively chooses the pooling field size in a convolutional network architecture according to the object scale (inversely proportional to the depth) so that small details can be preserved for objects at distance and a larger receptive field can be used for objects nearer to the camera. The depth gating signal is provided from stereo disparity (when available) or estimated directly from a single image. We integrate this depth-aware gating into a recurrent convolutional neural network trained in an end-to-end fashion to perform semantic segmentation. Our recurrent module iteratively refines the segmentation results, leveraging the depth estimate and output prediction from the previous loop. Through extensive experiments on three popular large-scale RGB-D datasets, we demonstrate our approach achieves competitive semantic segmentation performance using more compact model than existing methods. Interestingly, we find segmentation performance improves when we estimate depth directly from the image rather than using "ground-truth" and the model produces state-of-the-art results for quantitative depth estimation from a single image.
Download: pdf
Text Reference
Shu Kong and Charless C. Fowlkes.
Recurrent scene parsing with perspective understanding in the loop.
arXiv:, 2017.
URL:
http://arxiv.org/abs/1705.07238.
BibTeX Reference
@article{KongF_TR_2017,
author = "Kong, Shu and Fowlkes, Charless C.",
title = "Recurrent Scene Parsing with Perspective Understanding in the Loop",
journal = "arXiv:",
volume = "abs/1705.07238",
year = "2017",
url = "http://arxiv.org/abs/1705.07238",
tag = "geometry"
}