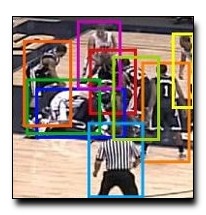
Accurately annotating entities in video is labor intensive and expensive. As
the quantity of online video grows, traditional solutions to this task are
unable to scale to meet the needs of researchers with limited budgets. Current
practice provides a temporary solution by paying dedicated workers to label a
fraction of the total frames and otherwise settling for linear interpolation.
As budgets and scale require sparser key frames, the assumption of linearity
fails and labels become inaccurate. To address this problem we have created a
public framework for dividing the work of labeling video data into micro-tasks
that can be completed by huge labor pools available through crowdsourced
marketplaces. By extracting pixel-based features from manually labeled
entities, we are able to leverage more sophisticated interpolation between key
frames to maximize performance given a budget. Finally, by validating the power
of our framework on difficult, real-world data sets we demonstrate an inherent
trade-off between the mix of human and cloud computing used vs. the accuracy
and cost of the labeling.
Download: pdf
Text Reference
Carl Vondrick, Deva Ramanan, and Donald Patterson.
Efficiently scaling up video annotation with crowdsourced marketplaces.
In
Proc. of the European Conference on Computer Vision. 2010.
BibTeX Reference
@inproceedings{VondrickRP_ECCV_2010,
author = "Vondrick, Carl and Ramanan, Deva and Patterson, Donald",
title = "Efficiently Scaling Up Video Annotation with Crowdsourced Marketplaces",
booktitle = "Proc. of the European Conference on Computer Vision",
year = "2010",
tag = "object_recognition,people"
}