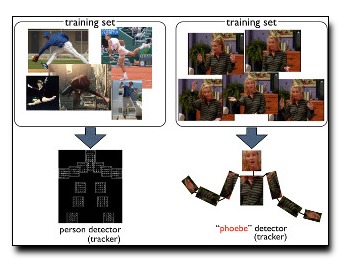
We address the task of articulated pose estimation from
video sequences. We consider an interactive setting where
the initial pose is annotated in the first frame. Our system
synthesizes a large number of hypothetical scenes with
different poses and camera positions by applying geometric
deformations to the first frame. We use these synthetic
images to generate a custom labeled training set for the
video in question. This training data is then used to learn
a regressor (for future frames) that predicts joint locations
from image data. Notably, our training set is so accurate
that nearest-neighbor (NN) matching on low-resolution
pixel features works well. As such, we name our underlying
representation “tiny synthetic videos”. We present quantitative
results the Friends benchmark dataset that suggests
our simple approach matches or exceed state-of-the-art.
Download: pdf
Text Reference
Dennis Park and Deva Ramanan.
Articulated pose estimation with tiny synthetic videos.
In
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2015.
BibTeX Reference
@inproceedings{ParkR_CVPR_2015,
author = "Park, Dennis and Ramanan, Deva",
title = "Articulated Pose Estimation With Tiny Synthetic Videos",
booktitle = "The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops",
year = "2015"
}