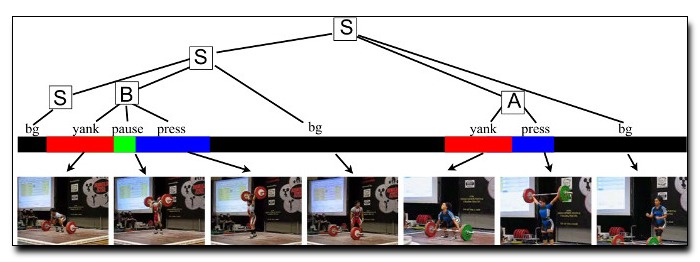
Real-world videos of human activities exhibit temporal
structure at various scales; long videos are typically composed
out of multiple action instances, where each instance
is itself composed of sub-actions with variable durations
and orderings. Temporal grammars can presumably model
such hierarchical structure, but are computationally difficult
to apply for long video streams. We describe simple
grammars that capture hierarchical temporal structure
while admitting inference with a finite-state-machine. This
makes parsing linear time, constant storage, and naturally
online. We train grammar parameters using a latent structural
SVM, where latent subactions are learned automatically.
We illustrate the effectiveness of our approach over
common baselines on a new half-million frame dataset of
continuous YouTube videos.
Download: pdf
Text Reference
Hamed Pirsiavash and Deva Ramanan.
Parsing videos of actions with segmental grammars.
In
Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, 612–619. IEEE, 2014.
BibTeX Reference
@inproceedings{PirsiavashR_CVPR_2014,
author = "Pirsiavash, Hamed and Ramanan, Deva",
title = "Parsing videos of actions with segmental grammars",
booktitle = "Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on",
pages = "612--619",
year = "2014",
organization = "IEEE"
}