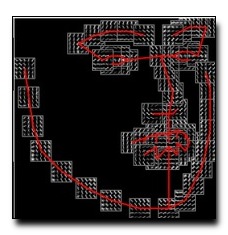
We present a unified model for face detection,
pose estimation, and landmark estimation in real-world, cluttered
images. Our model is based on a mixtures of trees with a shared pool
of parts; we model every facial landmark as a part and use global mixtures to capture topological changes due
to viewpoint. We show that tree-structured models are surprisingly effective at
capturing global elastic deformation, while being easy to optimize unlike
dense graph structures. We present extensive results on standard
face benchmarks, as well as a new "in the wild" annotated dataset, that suggests
our system advances the state-of-the-art, sometimes considerably, for
all three tasks. Though our model is modestly trained with hundreds of faces, it compares favorably to commercial systems trained with billions of examples (such as Google Picasa and face.com).
Download: pdf
Text Reference
Xiangxin Zhu and Deva Ramanan.
Face detection, pose estimation and landmark estimation in the wild.
In
IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2012.
BibTeX Reference
@inproceedings{ZhuR_CVPR_2012,
author = "Zhu, Xiangxin and Ramanan, Deva",
title = "Face detection, pose estimation and landmark estimation in the wild",
booktitle = "IEEE Conference on Computer Vision and Pattern Recognition (CVPR)",
year = "2012"
}