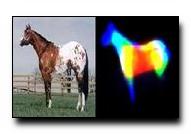
We consider the machine vision task of pose estimation from static images, specifically for the case of articulated objects. This problem is hard because of the large number of degrees of freedom to be estimated. Following a established line of research, pose estimation is framed as inference in a probabilistic model. In our experience however, the success of many approaches often lie in the power of the features. Our primary contribution is a novel casting of visual inference as an iterative parsing process, where one sequentially learns better and better features tuned to a particular image. We show quantitative results for human pose estimation on a database of over 300 images that suggest our algorithm is competitive with or surpasses the state-of-the-art. Since our procedure is quite general (it does not rely on face or skin detection), we also use it to estimate the poses of horses in the Weizmann database.
Download: pdf
Text Reference
Deva Ramanan.
Learning to parse images of articulated bodies.
In B. Schölkopf, J. Platt, and T. Hoffman, editors,
Advances in Neural Information Processing Systems 19, pages 1129–1136.
MIT Press, Cambridge, MA, 2007.
BibTeX Reference
@incollection{Ramanan_NIPS_2006,
author = "Ramanan, Deva",
editor = {Sch\"{o}lkopf, B. and Platt, J. and Hoffman, T.},
tag = "people,object_recognition",
title = "Learning to parse images of articulated bodies",
booktitle = "Advances in Neural Information Processing Systems 19",
publisher = "MIT Press",
address = "Cambridge, MA",
pages = "1129--1136",
year = "2007"
}